The Architecture of Authenticity: Mastering Synthetic Data Engineering for High-Stakes Simulations
Discover the technical framework behind high-fidelity synthetic data engineering for high-stakes simulations. As Generative AI transforms the data science landscape, the true challenge lies in architecting environments that reflect regional socioeconomic rhythms and operational messiness. This deep dive explores the engineering of the payday pulse, regional temporal engines, and intentional data friction used to build an AI-resilient datathon. Learn how contextual data modeling and adversarial prototyping can be used to validate human-led analytical depth over simple, AI-generated coding shortcuts.
SCIENTIFIC INSIGHTS INTO AI AND GEOSPATIAL TECHNOLOGIES
Scott Pezanowski
4/29/202610 min read
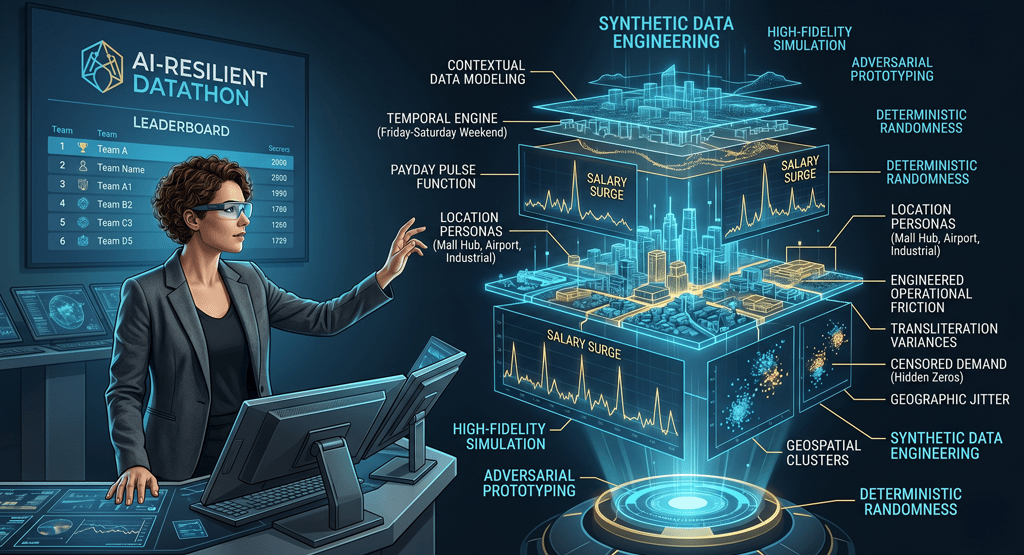
In the first part of this series, we talked about a major shift in how we think about technical skills: moving from Difficulty through Implementation to Difficulty through Synthesis. We’re living in the age of Generative AI and vibe coding, where almost anyone can use a few prompts to get a quick, though often surface-level, result. As a result, the role of the technical professional has fundamentally changed. The real value isn't just in writing code anymore; it’s in being the architect who designs the whole system and ensures the results are actually true.
But for a competition to really stand up to AI, the environment needs to be more than just a pile of numbers. It has to feel like a high-fidelity simulation of the real world. With a background in informatics, I see data as a living reflection of how people behave, how systems interact, and even how geography shapes our lives. When I was tasked with designing the challenges for a major regional bank’s datathon, I knew that a generic, clean dataset would be solved by a modern AI in minutes. To create a test that really measured someone's depth, we had to look past standard stats and engineer what I call Contextual Friction.
This post takes you under the hood to look at the technical side of our Synthetic Data Engine. I’ll show you how we built a world that was messy enough to feel real but structured enough to serve as a rigorous scientific benchmark for the next generation of data talent.
The Philosophy of Contextual Friction
Most of the time, when people generate synthetic data, they focus on statistical mirroring. They want to make sure the averages and patterns in the fake data look just like a real-world sample. While that’s great for privacy, it isn't enough for a high-level competition in 2026. If the data is too perfect, the patterns are too easy for a neural network or a smart coding assistant to find.
In the world of informatics, we focus on where people, information, and technology meet. To make this challenge AI-resilient, I intentionally injected the noise of reality that AI tools often ignore or oversimplify.
The goal wasn't to make the data hard just to be mean or chaotic; it was to make it operationally difficult. We wanted to reward the person who didn't just look at the columns of numbers, but actually asked: Why does the data look like this for a bank in this specific part of the world? This meant moving into behavioral modeling. We wanted to create a situation in which relying solely on prompts would yield a hallucinated or logically flawed solution, whereas applying real scientific rigor would lead to a win.


The Informatics of Synthetic Design: Modeling Socio-Technical Systems
Designing this engine meant we couldn't just treat a bank’s transaction logs as isolated bits of info. We had to see them as a socio-technical system. A transaction log is really just a digital footprint of human behavior, influenced by cultural traditions, local economy, and geography. If you take the human out of the loop, you lose the realism you need for a high-stakes competition.
To get this right, we focused on the Information Lifecycle. We looked at how money moves from a physical ATM to a central database and eventually to an analyst. In the real world, data loses its perfect quality as it moves through these steps. We simulated data entropy, that natural decay in quality, by adding in things like network glitches and ghost records that you’d find in any big company’s tech stack.
By building these realities in, we forced participants to really think about where their information was coming from. It wasn't just a coding test; it was a test of how well they understood the pipeline of truth. Today, being able to spot when data might be misleading or incomplete is a rare and valuable skill. We built this engine to find the people who can see the whole system, not just the spreadsheet.
The Temporal Engine: Tuning into the Local Rhythm
The first real layer of our simulation was what I like to call the Temporal Engine. If you’ve ever played around with standard AI-generated datasets or time-series templates, you’ve probably noticed they almost always assume a Western Monday-to-Friday workweek. But for a regional bank in this part of the world, that assumption is a total deal-breaker. If your data doesn't know which weekend it is, your accuracy will tank immediately.
To make our environment feel authentic, we hardcoded the regional Friday-Saturday weekend directly into our generator. Then, we layered in a precise three-year calendar of local public holidays. This wasn’t just about making the charts look local; it fundamentally changed the rhythm of the data.
A vibe-coded model that just follows a standard five-day cycle would get tripped up every single week. To succeed, participants had to do a Temporal Audit. They had to roll up their sleeves, look at the calendar, and build features that accounted for the local pulse. This was our first line of defense: an AI can write the code, but only a human with their eyes on the ground can provide the cultural and geographic context to make that code actually work.
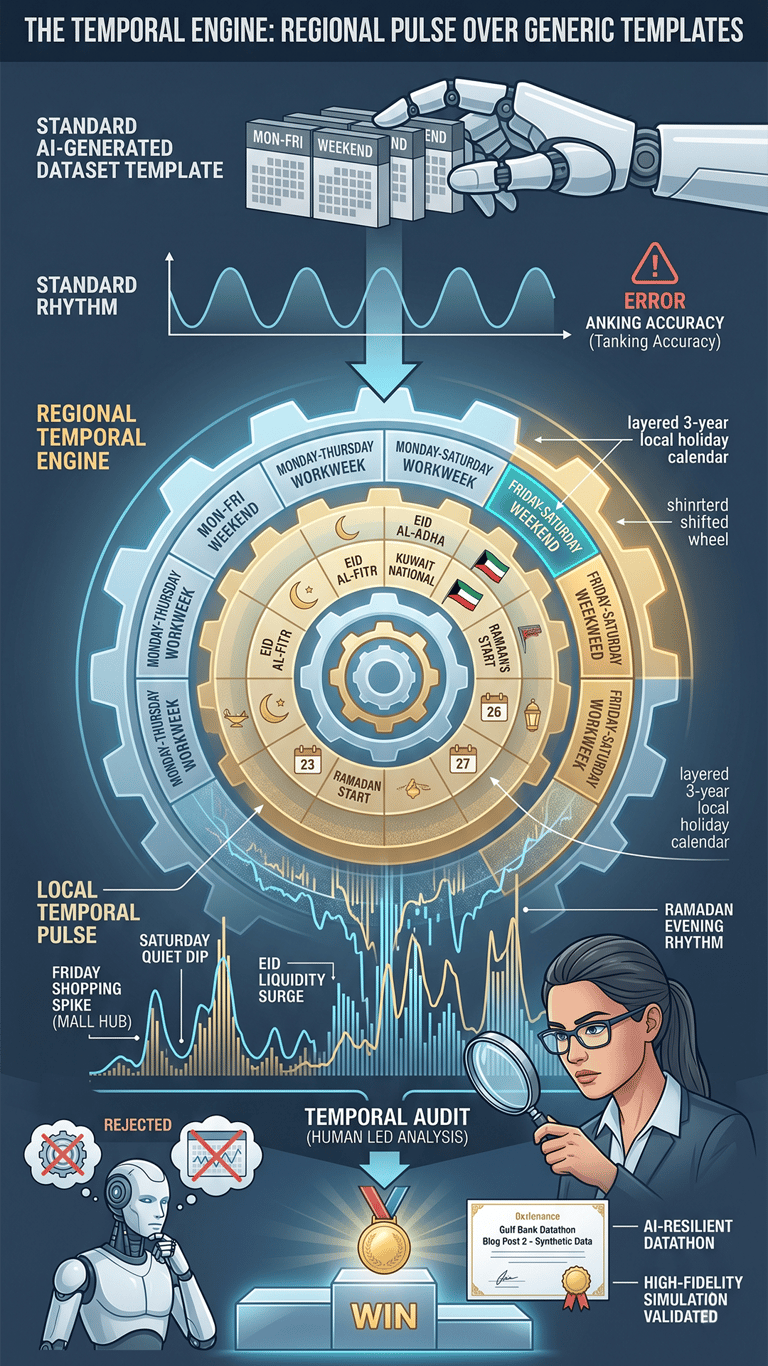
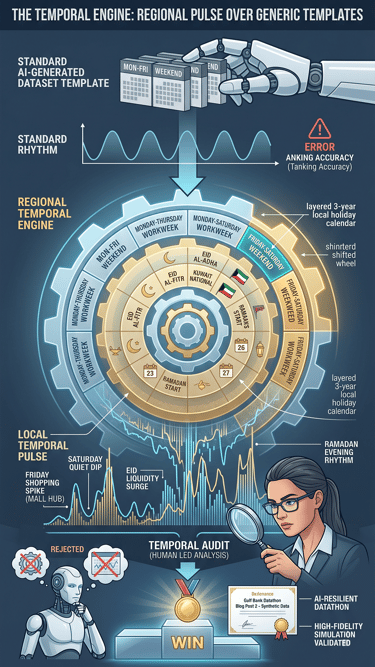
The real star of our predictive challenges was the ATM Cash Demand Forecast. In the real world, cash demand isn’t some smooth, predictable line; it’s a jagged, wild reflection of how we live our lives. The most important signal we built into our engine was the Payday Pulse.
In our region, there’s a massive surge in cash withdrawals that happens almost like clockwork between the 20th and 27th of every month when salaries are paid out. To capture this, we built a dedicated surge function into our data generation process. We didn't just add random noise; we injected a structured, periodic signal that simulated thousands of people hitting the ATM network at the exact same time.
The Mechanics of the Payday Pulse
By adding this logic, we created a hidden feature that acted as a litmus test for analytical depth. A generic AI assistant will usually suggest standard averages or simple trends. But those models completely miss the 25% jump on the 21st of the month unless a human steps in. To win, participants had to think beyond the code and build a Salary Window logic. It turned a math problem into a discovery problem, rewarding those who could hear the economic heartbeat amid the noise.
Beyond One-Size-Fits-All: Modeling Personas
While the payday pulse gave us the big picture, the real magic and messiness are in the details. One of the biggest mistakes people make in data science is trying to apply one single model to everything. To make our simulation more robust, we engineered Location-Based Profiles so that every ATM had its own unique personality.
We split our synthetic network into four distinct Personas:
The Mall Hub
These machines are high-volume and high-energy. They’re heavily influenced by the Friday-Saturday shopping rush and people staying out late.
The Residential Quiet-Zone
These stay pretty calm most of the time but are incredibly sensitive to the Payday Pulse.
The Airport Gateway
This persona operates 24/7. It doesn't care about weekends, but it’s perfectly synced with holiday flight schedules.
The Industrial Site
This one is a sleepy giant, near-zero activity most of the month, followed by a massive, single-day explosion on payday.
By injecting these personas, we gave the teams a hidden task: Segmentation. A model applied to the entire dataset would only yield a mediocre average. The teams that really stood out were the ones that acted like architects, realizing the dataset wasn't a monolith. They had to group the ATMs by their behavior before they even started predicting. It’s exactly what an architect has to do in the real world: understand the persona of the problem before deciding on the solution.
Engineering Messiness: The Data Engineer’s Obstacle Course
For the Data Engineering track, we moved from the world of forecasting into the bank's technical engine room. In a world where AI can write a perfect SQL query in seconds, we had to move from testing clean code to testing resilient architecture. We did this by intentionally making the data dirty in ways that only a human could truly untangle. We focused on three types of what I call operational friction:
The Spelling Maze (Transliteration): In a bilingual business world, names are rarely consistent. One record might say Al-Rai Restaurant, while another says ALRAI RESTAURANT or Al Rai Rest. A simple database join would miss these connections entirely. We built a script that programmatically varied these names across 100,000 records. To win, participants had to architect a pipeline that used fuzzy matching, proving they knew how to handle the real data that companies actually deal with.
The Hidden Zero (Censored Demand): This is one of my favorite challenges. We engineered Cash-Out Events where an ATM would run out of money. In the logs, this just looks like zero transactions. But as any banking professional knows, a zero doesn't always mean no one wants cash; it often means the machine is broken or empty. If a contestant's AI model treated that zero as a true drop in interest, their future forecasts would be way off. We forced teams to use their judgment to uncensor the data and see the operational failure behind the number.
The Geographic Jitter: We added a little vibration to the latitude and longitude coordinates of our ATMs. It sounds small, but it prevented teams from using simple address matching. Instead, they had to use geospatial libraries to cluster machines by their actual proximity. It was a perfect test to see if they had the right technical tools in their stack to handle imperfect, real-world locations.
Adversarial Prototyping: Breaking It Before They Do
As an advisor, I live by a simple rule: you can’t release a high-stakes challenge until you’ve tried your hardest to break it yourself. In the age of Generative AI, this means Adversarial Prototyping. Before the datathon even started, I served as a Malicious Participant. I grabbed the latest AI models and tried to solve every track with the simplest prompts possible.
If the AI could get a top-tier score with a lazy command like Write a Python script to solve this, I considered that problem broken. We would then go back to the drawing board and add more complexity, tightening the payday pulse window or adding noise to the data, until the AI couldn't solve it without a human architect leading the way. This ensured that on game day, the magic of a quick prompt wouldn't be enough to win.
Making It Fair: The Math of Seed Control
When you have over 100 teams competing for a top spot, fairness is everything. If one team gets a dataset that’s even slightly cleaner than another’s, the whole leaderboard loses its integrity. To keep things perfectly fair in such a messy synthetic world, we used Deterministic Randomness.
Even though the data felt unpredictable, every single glitch or spelling error was perfectly reproducible. We controlled this using a hierarchy of random seeds in our code.
This meant the ground truth was the same for everyone, whether they were working on their own laptops or in the enterprise cloud environment we provided. When a team’s score went up, we knew it was because of their logic, not a lucky roll of the dice.
A Collaborative Effort
Building this high-fidelity simulation wasn't a solo mission. It was a massive collaborative effort between our financial institution, a leading private university, and a premier software training academy. While I focused on the scientific design of the data signals, our partners focused on the Deployment Architecture. We treated the engine like a live product launch, using automated pipelines to push updates as we finished our stress tests. This collaborative friction was essential; it kept the tasks scientifically grounded but also industry-ready.
The Human in the Machine
Designing the Synthetic Data Engine for this datathon was a masterclass in how much technical work has changed. It proved that in the age of AI, being a coder isn't enough anymore. The AI is already a great coder.
The real value I provided as an architect wasn't in writing the Python scripts; the AI helped with that. The value was in the Synthesis:
Recognizing the Two-Hour Trap and designing a deeper challenge.
Modeling regional nuances like the salary cycle and local weekends.
Engineering intentional friction to make sure the human stayed in control.
We are entering an era in which human-computer collaboration is the baseline for all high-value work. In this new landscape, your worth is measured by the quality of your constraints and the rigor of your verification. If you treat AI as magic to provide answers, you will produce shallow, risky, and generic results. But if you treat AI as a co-architect, a partner to be challenged, stress-tested, and steered, you can produce work that is truly professional-grade.
The datathon was a success, not because the participants used AI, but because we designed a world where they had to use it as a multiplier for their own human judgment.
In my next post in this series, I will go under the hood of our synthetic data engine. I’ll share the exact logic we used to build a digital twin of a nation’s ATM network and the specific Python frameworks we used to simulate a reality that was messy enough to be real, yet structured enough to be judgeable. Stay tuned as we explore how to build the data that builds the future.